
文字コード
コンピュータが直接扱えるのは、0と1で表わされる2進数だけです。一方、人間は、数値以外のデータである文字、音、色などもコンピュータで取り扱いたいわけです。そこで、文字、音、色などの数値でないデータを2進数の数値を使って表すために、符号化(以下、コード化)という工夫が必要になります。
コード化は、コンピュータを使う人間が自由勝手に行うこともできますが、それだと、機種や端末装置が変わったり、インターネット等を介して相互に情報をやりとりすると、正しく表示されない(このことを一般に「化(ば)ける」といいます)事態になります。
ですので、一般的には、コード化は予め決められた符号化のルール(文字コード体系)に従って行います。
ここでは、文字(文字の中には10進数の数字も含まれます)のためのコード化について解説します。
コンピュータの世界では統一的な文字コード体系が定められていますが、残念なことに、1種類ではなく、代表的なものだけでも数種類あります。皆さんの中で、パソコンを利用している際に、「文字化け」を経験したことはありませんか。これは、文字コード体系が複数あるのが原因なのです。
以下、代表的なものを紹介します。
なお、コンピュータでは2進数ですが、それだと長くなり、また読みにくいので、16進数で表記します。
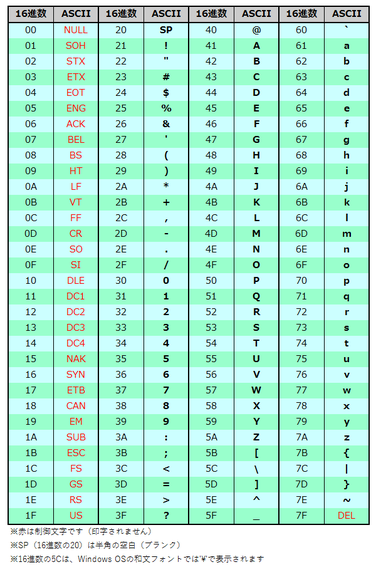
ASCII
ASCII(American Standard Code for Information Interchangeの略で、アスキーと呼びます)は、米国で生まれた文字コード体系で、文字コード体系の元祖です。
英数記号の1文字を7ビットで表すもので、大文字・小文字の英字、数字、記号といった文字が95個(内、1個は空白文字)と、33個の制御文字の計128文字が規定されています。
制御文字は、表示するための文字種ではなく、モニタやプリンタなどの入出力装置を制御するためのものです。
【便利知識】
1バイトは8ビットですが、英字・数字・記号を扱うには7ビットあれば十分なので、データ長を短くしてデータ通信の負荷を軽減するとともに、残り1ビットをデータ通信の誤り検出(パリティチェックといいます)のために役立てるという工夫が感じられます。
【便利知識】
Windows OSの和文フォントで、ASCIIの16進数の5C(本来は半角バックスラッシュ'\')の場所に、半角の円記号('¥')を割り当ててしまったために、Windowsパソコンでは半角バックスラッシュが使いづらいです。
Excelでは、その場所だけ和文フォント以外のフォントに変えると半角バックスラッシュで表示できます。
(筆者のパソコンでは、Word、PowerPointではこの方法がうまくいきませんでした。全角バックスラッシュ('\')のフォントやフォントサイズを変えるなどで、半角バックスラッシュに見せかけるしかないのかもしれません。ちなみに、'\'は「すらっしゅ」と入力して変換キーを押せば出てきます。)
ホームページ上では、逆に半角円記号が半角バックスラッシュで見えてしまうことが多いです。
特に半角にしなければならない時以外は、円記号もバックスラッシュも、全角にした方が無難です。
日本語用のJIS規格
米国で生まれたコンピュータは、次いでヨーロッパや日本などに広がり、今では全世界に広がっています。そうすると、各国の言語に対応が必要となり、ASCIIでは全く不十分になりました。
西欧諸国では、ASCII文字セットを8ビットに拡張し、増えた領域にヨーロッパ諸国で使われる文字を定義した「ISO-8859」という文字セットが使われています。追加する文字の種類によって、西欧諸国で使用する規格、東欧諸国で使用する規格、北欧諸国で使用する規格、ロシア語の規格、など16種類の規格が制定されています。
JIS X 0201
日本でも日本工業規格(JIS)によって、同様にASCII文字セットを8ビットに拡張し、増えた領域に(半角の)カタカナ文字と句読点などの記号を規定した、JIS X 0201という規格が制定されました。
現在ではこの規格が単独で使用されることはほとんどありませんが、Shift-JIS文字コード体系やEUC-JP文字コード体系の一部に組み込まれて用いられています。
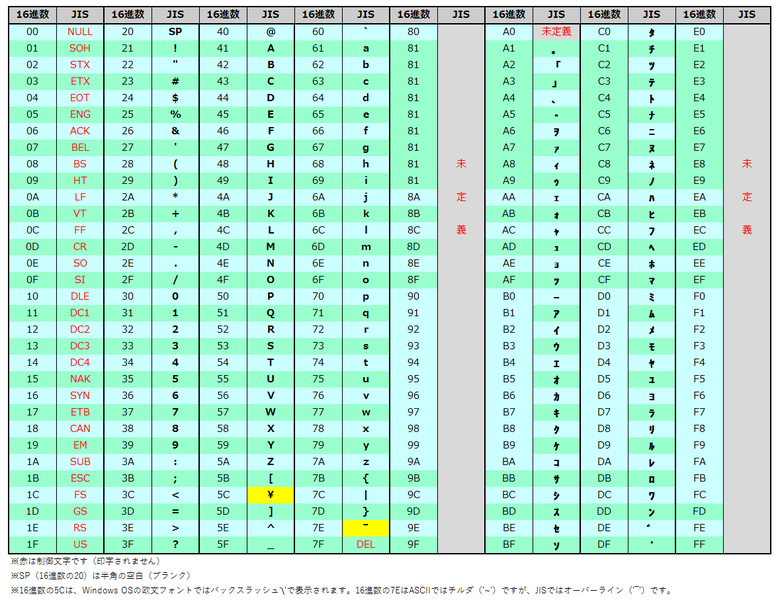
JIS X 0208(通称 JIS漢字コード)
JIS X 0201では、ひらがなや漢字が扱えません。
漢字のように何千文字もあるような文字体系は、1バイトのコードでは対応不可能で、2バイトコード体系の開発が不可欠でした。1バイトでは最大256文字しか入りませんが、2バイトあれば理論的には最大65,536文字まで入ります。2バイトコードの実用化は日本語や中国語、韓国語の情報処理にとって大きなステップでした。
1978年、JISは、2バイトのコード体系で、ひらがな、漢字(約6,000字)、数字や英字の全角文字などを規定する、JIS X 0208という文字コード体系を規定しました。通称として、JIS漢字コードとか、JIS第1第2水準漢字などと呼ばれるものです。
具体的には、第1バイトと第2バイトの、ともに16進数表記で21~7Eのそれぞれ94個、全体では94×94 =8,836個の文字を表すことができる領域に、6,879文字を割り当てています。
【便利知識】
2000年にJIS X 0208コード体系に約4,000文字を追加した拡張規格としてJIS X 0213が制定され、2004年に一部改訂されました。 2000年版をJIS2000、2004年版をJIS2004と称することもあります。

シフトJIS(Shift_JIS)
2バイトコードができたからといって、従来の1バイトコードを捨てて、全てが2バイトの世界になるわけにはいきません。プログラムのコンパイラやインタプリタなどは、相変わらずASCIIのような1バイトコードをベースとして動くので、過去の資産との互換性が求められます。
シフトJISは、日本の1バイトコード体系のJIS X 0201と2バイト漢字コード体系のJIS X 0208とを組み合わせて運用する方式です。この規格をShift_JISといいます。
シフトJISの漢字コード体系は、JIS漢字コード体系の表を、8000代(具体的には8140以降)、9000代(同9040以降)、E000代(同E040以降)、F000代(同F040以降)に分散して、移動(シフト)した形になっています。
なぜ、このような位置に漢字コード体系をシフトさせているかというと、JIS X 0201コード体系で、80~9F、E0~FFの欄が未使用になっているからです。
例えば、「JIS漢字コード」という文字を、JIS X 0201表とJIS漢字コード表を使って、16進数に変換すると、「4A 49 53 34 41 3B 7A 25 33 21 3C 25 49」となります。
(分かりやすくするため、間に空白を入れました。)
これを、1バイトコードと思って、JIS X 0201表で文字に変換していくと、「JIS4A;z%3!<%I」となってしまいます。
同じく、「JIS漢字コード」という文字を、シフトJIS漢字コード表を使って、16進数に変換すると、「4A 49 53 8A BF 8E 9A 83 52 81 5B 83 68」となります。
これを、1バイトコードと思って、JIS X 0201表で文字に変換しようとすると、「JIS」に変換した後の16進数「8A」が未定義であることに気づき、これは2バイトコードと解釈して、シフトJIS漢字コード表を探して「漢」に変換するのです。以下同様に、1バイトコードなのか、2バイトコードなのかを判断して、JIS X 0201表とシフトJIS漢字コード表を使い分けることで、正しく変換ができるのです。
【便利知識】
JIS X 0208表の代わりに、文字数が拡張されたJIS X 0213表に準じたシフトJISコード体系が使用されることもあります。この規格をShift_JIS-2004といいます。
【便利知識】
UNIX OS(WebサーバなどのOSとして利用されることが多かった)のために開発された日本語用文字コード体系に、EUC-JPという規格があります。これは、ASCIIコード体系とJIS X 0208コード体系を組み合わせたものと言えます。

【便利知識】
シフトJISは、マイクロソフト社と日本企業数社が協力して1982年に誕生しました。そして、MS漢字コードとも呼ばれ、Windows OS(日本語版)の標準として活躍してきましたが、一方で、インターネットで世界中が繋がり、Webサイトなどを通じて多数の言語に触れる機会が増し、Webサイトなどの閲覧、メールやWord等の文書データの閲覧時に、しばしば文字化けが発生するようになってきました。
シフトJIS自体も、もともと未使用の1バイトコードがあったことを利用したアクロバティカルな方式で、登録されている文字数に限りがあることと、文字が規定されていない空きエリアを利用して、種々の外字が登録されていき、多数の亜流の文字コード体系が生まれてしまい、標準としては限界に近づいています。
このような背景と、後述のように、世界共通の標準的なコード体系の制定という動きに応じて、まもなく、シフトJISはWindowsの標準ではなくなる運命にあります。
UTF-8
世界で使われる全ての文字を共通の文字コード体系で利用できるようにしようという考えから、ゼロックス、マイクロソフト、アップル、IBM、サン・マイクロシステムズ、ヒューレット・パッカード、ジャストシステムなどが参加したコンソーシアムによって、Unicode(ユニコード)という符号化文字集合や文字符号化方式などを定めた文字コードの業界規格が、1991年に誕生しました。
単一の大規模な文字セットであることが特徴で、世界各国の現代の文字だけでなく、古代の文字や歴史的な文字、数学記号、絵文字(ガラケーで使用されているものも)などにも対応しています。
国際規格のISO/IEC 10646とUnicode規格は同じ文字コード表になるように協調して策定されています。
Unicodeは、Unix、Windows、macOS、Javaなど種々のOSで利用されており、文字符号化方式も標準化されていて、いくつかの亜種があったShift_JISやEUC-JPの混乱のようなものは回避されています。
Unicodeは当初、1文字を2バイト(16ビット)の固定長で表す規格のコード化方式で考えられ、UTF-16(Unicode Transformation Format-16)と名づけられました。ただ2バイトでは、最大で約6万字の文字しかサポートできないので、結局、2バイト固定長という原則を崩すことになりました。基本的には(名前の通り)2バイトで1文字を表すのですが、「サロゲート」と呼ばれる拡張領域内の文字を利用する場合は1文字を4バイトで表します。つまり、UTF-16は2バイト表現と4バイト表現が混在したコード変換方式です。
UTF-16はASCII文字も1文字2バイトで表現します。つまりASCIIコードと互換性がありません。そのため、ASCIIコードを想定したプログラムで誤動作を起こす可能性があります。そこでASCII文字については、ASCIIと同様のコードを割り当てるようにしたコード変換方式が考えられました。それがUTF-8です。
UTF-8は1~4バイトで1文字を表し、漢字や仮名の1文字は3バイトを要します。シフトJISでは漢字や仮名は2バイトでしたので、日本語の文書などでは、データサイズが1.5倍程度に増大することになります。
Unicodeには他に4バイト固定長で処理するUTF-32やUCS-4 などの方式も規定されています。
【便利知識】
上述までの解説でお分かりのように、現在の文字コード変換の標準は、UTF-8に集約されつつあります。文字コードはUTF-8にするという考え方でいけば、文字化けも起こりにくいと言えましょう。